Task
To compare the performance of EC2 Load Balanche on-host TLS termination reverse proxy on x86 and Arm(aarch64).
I devided TLS performance into two dimensions,
- bulk data encryption. Mostly about symmetric crypto(cipher) perf like AES.
- TLS handshake. Mostly about asymmetric crypto perf like ECHDE, RSA.
Perf Event
I learn Perf event from Brendan Gregg’s blogs,
http://www.brendangregg.com/perf.html Intro to perf evnets, which is the source of truth.
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html Flame Graph is just a way of representing the data we collected from perf event tools.
http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
Higher sample rate causing higher overhead. Freqency value 99 and not 100 is to avoid lockstep sampling, which can produce skewed results.
Troubleshooting - Missing function name
If you are only seeing, for e.g. no function name but only address,
57.14% sshd libc-2.15.so [.] connect
|
|--25.00%-- 0x7ff3c1cddf29
http://www.brendangregg.com/perf.html#Symbols
Always compile with frame pointers. For C program, either
- Recompile with
-fno-omit-frame-pointer. - Install debuginfo for the software with DWARF data and use perf’s DWARF stack walker.
What is Frame pointers?
Actually the symbols we are able to see in the perf report, because,
- During function call, code will store a frame pointer (in fp register on Arm), which contain the stack pointer just before the function was called. wiki
- So by just “peeking” on the current frame pointer periodically, we can know what the current running function and thus calculate the time period base on our “peeking” frequency.
- Since frame pointer is just an address, we need further translate the address to a human-readable function name.
Linux下Call Stack追溯的实现机制 大家都知道当发生函数调用的时候,函数的参数传递,返回值传递都要遵循一定的规则,在ARM体系架构下,这个规则叫做Procedure Call Standard for the ARM Architecture。在这个规则里规定了函数调用的时候,返回地址在LR里面,第一到第四个参数在r0~r3里面,第五到第八个参数在Stack里面,返回值在r0里面。这是基本规则,C编译器产生汇编指令是必须遵循这些规则,这也是ABI(Application Binary Interface)的一部分。另外,为了实现连续的函数调用,如fun_a()->func_b()->func_c(),每个函数的入口处必须先把LR压到stack里,否则func_b()调了func_c()之后,LR变成了func_c()的返回地址,而func_b()返回地址就丢失了。
Perf stat
https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。如果您认同这些说法的话,Perf stat 应该是您最先使用的一个工具。它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
$ perf stat ./t1 262.738415 task-clock-msecs # 0.991 CPUs 2 context-switches # 0.000 M/sec 1 CPU-migrations # 0.000 M/sec 81 page-faults # 0.000 M/sec 9478851 cycles # 36.077 M/sec (scaled from 98.24%) 6771 instructions # 0.001 IPC (scaled from 98.99%) 111114049 branches # 422.908 M/sec (scaled from 99.37%) 8495 branch-misses # 0.008 % (scaled from 95.91%) 12152161 cache-references # 46.252 M/sec (scaled from 96.16%) 7245338 cache-misses # 27.576 M/sec (scaled from 95.49%) 0.265238069 seconds time elapsed上面告诉我们,程序 t1 是一个 CPU bound 型,因为 task-clock-msecs 接近 1。 对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息:
Task-clock-msecs: CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。 Context-switches: 进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。 Cache-misses: 程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好 CPU-migrations: 表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。 Cycles: 处理器时钟,一条机器指令可能需要多个 cycles, Instructions: 机器指令数目。 IPC: 是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。 Cache-references: cache 命中的次数 Cache-misses: cache 失效的次数。
https://perf.wiki.kernel.org/index.php/Tutorial
THE MAN PAGE!
https://perf.wiki.kernel.org/index.php/Tutorial#Attaching_to_a_running_process
If no run during sampling time than 0 event. On any Intel or AMD processor, the cycle event does not count when the processor is idle, i.e., when it calls mwait().
https://perf.wiki.kernel.org/index.php/Tutorial#Sampling_with_perf_record
This generates an output file called perf.data. That file can then be analyzed, possibly on another machine, using the perf report and perf annotate commands. The model is fairly similar to that of OProfile. perf record by default using cycles like defined in perf stat.
How I use perf to compare the same app on diff CPU?
It’s actually tricky to do it. I choose to use perf because it’s already known that our app has some performance regression on Arm but we just want to use why. So we want to break down the performance regression into different parts to give us detailed view.
For e.g. we want to get some data like - function A perform 200% worse on Arm (cost 10ms CPU time on Intel vs. 20ms on Arm), contribute 25% of the regression (the total perf delta is 40ms, this 20-10=10ms delta is 25% of the reason).
To achieve this,
- We need to make sure we are always benchmark under the same workload. For TLS handshake, if we perf record same amount of time, say 60 sec, we need to make sure the same number of handshake has been handled during this time, say 1 handshake per sec.
- Perf record as precisely as possible. Say if our app has a worker thread that is dedicated to TLS handshake, we can perf this only thread to avoid noise and overheads.
- Make sure that our app is running exactly the same workload by elimate all the possible variables. Like if we should turn off “smart” scheduler, task queue(which can lead delayed processing), async processors, Hyper Threading, other apps on the same CPU core/system, etc. All in all, we want to make sure the
- exact same code has been executed,
- under exact same frequency,
- on the exact CPU(s)
- In the case we can’t enfore the same function operating freqency, we can record a longer period to cover all the workload to achieve eventual same workload,
- e.g. During bulk data transfer test, both CPUs are trying best to do the encryption by use 100% CPU. However, result in a different MB/s of encryption. So even for same workload, say 1GB downloading test, one CPU is faster. So in this case, we can’t
pref recordthe same period of time, instead, we should start the recording before the task start and end recording after both CPUs got the job done. - Say on Intel we use 100s and on Arm we use 250s, we can record for max(100, 250)=250 to make sure the
perf statstill comparable, sinceperf statis showing the absolute CPU cycle/task_cycle, no matter the total length of period. - However, since recording time is longer than load testing time, the actual real-time CPU % usage is higher than what recorded in perf stat. For example, we might see 0.5 CPU utilized in
perf stat, but actual real-time CPU usage show intopcan be 75%. It might due to that the CPU % load in 20s has been “amortized” into 30s.
- e.g. During bulk data transfer test, both CPUs are trying best to do the encryption by use 100% CPU. However, result in a different MB/s of encryption. So even for same workload, say 1GB downloading test, one CPU is faster. So in this case, we can’t
- Since perf report only show the % taken by each symbol(e.g. function_name, dso_filename), how to compare a the CPU absolute time(aka. wall-time) taken by each symbol? For a CPU at 1% load, a task costing 50% overhead means it costs 0.5% cpu wall-time.
- We can get CPU time for the whole process/thread
- We can get % for each symbol running in this process/thread
- then, multiply % with CPU time for absolute CPU for each symbol!
I didn’t find there’s any other ones did this multiply trick. So I first think about it.
stackoverflow/profiling-for-wall-time-on-linux
stackoverflow/thread-utilization-profiling-on-linux
stackoverflow/using-perf-to-record-a-profile-that-includes-sleep-blocked-times
Off CPU profiling question?
stackoverflow/unknown-events-in-nodejs-v8-flamegraph-using-perf-events/
stackoverflow/finding-threading-bottlenecks-and-optimizing-for-wall-time-with-perf
stackoverflow/best-event-counter-to-use-for-measuring-wall-clock-time-using-perf-tools
Acutally usingtask-clockis not right. It still can’t tell us how manytask-clockhas been ticked in a wall time second, thus we still can’t get the wall CPU time. Also btw,
-e constant_tscnot exist on Intel-e nonstop_tscnot exist on Intel-e task-clockseems better to be used for multiplier as it’s only triggered when task is ON-CPU.stackoverflow/how-to-use-linux-perf-tool-to-generate-off-cpu-profile
Brendan Gregg mentioned off-cpu time. https://github.com/brendangregg/FlameGraph/issues/218
Still off-cpu.
what-does-1-234-cpus-used-mean-in-perf-output
linux-perf-events-cpu-clock-and-task-clock-what-is-the-difference
brendangregg.com/hotcoldflamegraphs
github/FlameGraph/issues/47
brendangregg.com/linux-perf-off-cpu-flame-graph
http://www.brendangregg.com/offcpuanalysis.html
Idle time also count as off-CPU!
github/iovisor/offcputime_example stackoverflow/profiling-sleep-times-with-perf https://perf.wiki.kernel.org/index.php/Tutorial#Profiling_sleep_times how-to-get-absolute-values-instead-of-percentages-in-perf
get-total-cpu-usage-of-an-app-from-perf
perf-doesnt-add-up-to-100
Result
| Intel | Arm | |
|---|---|---|
| CPU wall-time by perf stat | 5% | 20% |
| Relative ECDH | 15% | 50% |
| Relative RSA | 55% | 40% |
| Relative Others | 30% | 10% |
| Absolute ECDH | 0.75% | 10% |
| Absolute RSA | 2.75% | 8% |
| Absolute Others | 1.5% | 2% |
- We get CPU wall-time by
perf stat - We get “Relative ECDH” by
perf record+perf report+ Flame Graph to see the ECDH related function symbols consumed what % of CPU time out of 100%. Say on Intel, ECDH has a 15% bar on Flame graph. Absolute ECDH == CPU wall-time ✖️ Relative ECDH
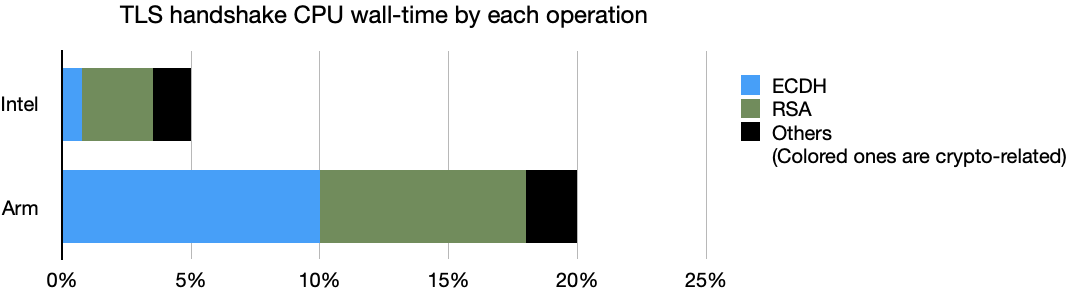
So we can make a clear conclusion that for our app, Arm CPU work 400% “harder” to finish the same workload, and mostly “struggle” to finish ECDH and RSA related functions. But the “absolute others” are basically the same. So we can draw the conclusion that our Arm procressor is bad at asymmetric cryptos like RSA and ECDH.
One-liners
perf report --sort=dsoreport by dynamic shared object.- get total event by
perf report -D -i perf.data | fgrep RECORD_SAMPLE | wc -l. Be awaresample_rateis just target rate, not a stable rate. - We can
perf statunder different load and period to see if the load distribution is stable. - view specific process and it’s child processes/threads to find the worker threads
sudo top -H -p $PID,sudo pstree -lps $PID - Perf a -
thread,sudo perf record -F 249 -t worker_thread_pid --call-graph fp -- sleep 30,sudo perf record -F 249 -t worker_thread_pid --call-graph dwarf -- sleep 30,sudo perf stat -t PID -- sleep 30
Advance Topics
动态追踪技术漫谈 - 章亦春 讲解了 Dynamic Tracing 的历史和所有技术。此文更加重视可编程的动态追踪,比固定的得到 Frame pointers 统计信息的 perf event 更加高效。